


 今日热搜
今日热搜



2025 年的 AI 图像创作领域,正陷入一场“能力割裂”的竞争迷局。以 Stable Diffusion 为代表的开源阵营凭借生态优势占据开发者市场,却受困于抽象概念理解的天然短板;谷歌 Nano Banana等闭源标杆虽在编辑精度上见长,却存在多模态协同的明显局限且商用授权成本高昂;而 Midjourney 等工具专注于设计美学表达,但因缺乏可编辑能力,在创作场景中表现受限。
行业迫切需要一个能打破“开源功能弱、闭源门槛高”困境的突破性存在——而这把破局的钥匙,握在香港本地 AI 研究团队手中。
近日,港科大贾佳亚团队推出DreamOmni2 ,让港产 AI 首次站在了全球视觉生成领域的竞争核心。这款港产 AI 神器,不仅在文字指令编辑、实体物件生成等传统赛道保持顶级水准,更以“抽象概念精准还原”与“多图协同无缝衔接”的核心能力,击破了行业长期存在的技术桎梏,不仅全面碾压主流开源模型,更在多模态编辑任务中击败谷歌 Nano Banana 等商用标杆。开源仅两周便斩获 GitHub 1.6k 星标,被全球创作者疯狂喊出“King Bomb”的背后,是港产 AI 凭借系统性创新,对全球技术格局发起的一次关键性挑战,更印证了香港在 AI 领域的科研实力。
YouTube、国际AI创作社群齐赞“King Bomb”
开源两周,DreamOmni2在技术社区和海外创作圈掀起讨论热潮,“King Bomb”的称号更是从社群中快速传开。
在衡量开源项目热度与认可度的 GitHub 平台上,DreamOmni2 的表现尤为亮眼:上线后迅速积累 1.6k 星标,这一数据在同类图像生成开源模型中处于绝对上游水平。要知道,不少专注垂直领域的 AI 开源项目需数月才能达到类似关注度,而 DreamOmni2 仅用极短时间便实现突破,足见全球开发者的认可。
而YouTube 上,技术博主 T8star 专门发布视频,将其称为“真王炸”,详细演示其多模态图像编辑能力,盛赞它“对抽象概念的理解力超强”。

 在 Reddit 的 StableDiffusion 板块(全球知名 AI 创作社群),有用户感慨:“图像和文本都能下达指令的时代终于来了!DreamOmni2 简直要颠覆图像生成与编辑的常识”,还有用户强调它零样本风格迁移效果好得令人惊讶。
在 Reddit 的 StableDiffusion 板块(全球知名 AI 创作社群),有用户感慨:“图像和文本都能下达指令的时代终于来了!DreamOmni2 简直要颠覆图像生成与编辑的常识”,还有用户强调它零样本风格迁移效果好得令人惊讶。
此外,Twitter(X 平台)上,来自全球的设计师、开发者纷纷晒出作品,直言这款模型“重新定义了开源 AI 的创作能力”:“用 DreamOmni2 时,终于不用费劲想怎么描述细节了,一张参考图+一句话,效果比之前的模型好太多!”评论中不断出现“重新定义开源 AI 创作能力”“比很多闭源模型更好用”的评价,进一步推高了该模型在海外的讨论热度。
从生成到编辑从实体到抽象,DreamOmni2 远超想象
这款让创作者们纷纷喊出“King Bomb”的港产 AI 到底凭什么让行业疯狂?一系列的实测让它的硬实力无处可藏,无论是多图参考的细节编辑,还是按指令的场景生成,DreamOmni2 都能把“AI 懂创意”变成看得见的效果。
“想让人物发型有 90 年代港风的蓬松感,怎么描述 AI 都做不出来”“参考图里的莫兰迪色调很美,但 AI 只能复制物体,复制不了氛围”——这是无数设计师、内容创作者用 AI 时的烦恼。
而 DreamOmni2 直接打破了这限制:支持“文字+多张参考图”一起输入,比如想让模特穿的裙子有参考图里丝绸的光泽,只要上传图片、简单描述,AI 就能精准捕捉;面对抽象需求,也能通过分析参考图生成符合预期的效果,真正让 AI 从“简单生图”变成“懂创意”。
在多模态生成任务中,需求是“图 1 中的猫与图 2 中的狗并排坐著,背景设定在车内,且生成图像的风格需与图 3 保持一致。”——DreamOmni2 不仅保持了图1图2原有的动物毛发特征,像图3一样的绘画风格,融合之后的背景色彩也十分一致。

再来一个更具挑战的测试,需求为“让图1中的汽车拥有与图2中的鼠标相同的图案”。这类任务考验的不只是模型的图像生成能力,更是对跨物体的语义映射、图案元素的空间迁移,以及复杂视觉信息的精准匹配能力。最终生成结果显示,DreamOmni2 依然表现不错,整体比例、纹理走向与汽车车身轮廓完美适配,实现了跨物体图案复用的高保真效果。

而在同类型模型对比测试中,我们以“图2中的人物正拿著图1里的物品”为指令,对 DreamOmni2 与 GPT-4o、谷歌 Nano Banana 等国际标杆模型进行横向对比。结果显示,GPT-4o 的 AI 合成痕迹较为明显,不仅人物脸部特征与原图偏差较大,整体脸型比例也存在不协调问题;谷歌 Nano Banana 虽能基本保持人物五官完整性,但生成的人物体态在背部弯曲度上出现显著失真;而 DreamOmni2 则精准捕捉到人物与物品的层级逻辑,不仅完美执行指令完成物品握持动作,更在完整保留人物脸部特征与原始姿态的基础上,自然融入符合场景的光影质感,在参考对象一致性与指令遵循度两大核心测试维度上,均展现出最优表现。

数据更印证了这点:在具体物体生成、抽象属性编辑等核心任务中,DreamOmni2 的得分都是最高的,不仅打败了当前所有主流开源模型,部分指标甚至超过了谷歌闭源的 Nano Banana。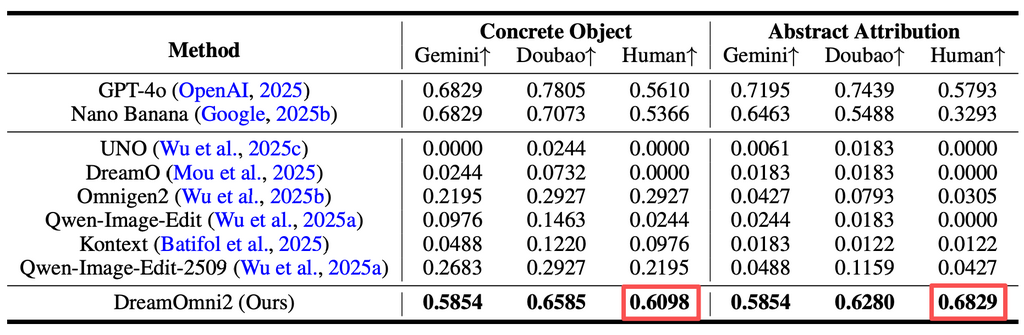
技术破壁:三阶段创新筑起“护城河”
能让 DreamOmni2 在生成、编辑、抽象理解三大维度全面超越同类模型,核心在于贾佳亚团队从数据构建、框架设计到训练策略的系统性创新,彻底解决了行业长期存在的“抽象数据稀缺”“多图协同难”“指令理解偏差”三大痛点。
首先解决的是多模态任务“缺好数据”的老大难问题——过去模型训练用的数据,要么没有参考图,要么只能覆盖具体物体,抽象概念数据严重不足。团队创建了“三阶段数据构建范式”:第一阶段用“特征混合”技术,生成同时包含具体物体(比如杯子)和抽象属性(比如磨砂质感)的图像对;第二阶段模拟真实创作场景,构建“参考图+要修改的图+修改后的图”的完整数据链;第三阶段整合多张参考图,让模型学会从多个参考中提取信息。这套流程不仅填补了抽象概念数据的空白,还确保数据符合真实使用场景,让模型训练更高效。
在模型框架上,DreamOmni2 也针对“多图参考”做了专门优化。原来的基础模型 FLUX-Kontext 无法区分多张参考图,团队就在位置通道里加了“索引编码”,让模型能精准辨认“图 1 是参考质感,图 2 是参考色调”;还根据参考图的大小动态调整位置编码,避免出现“把图 1 的像素直接复制到图 2”的混乱问题。另外,考虑到用户指令常常不规则(比如“帮我把这里弄得温暖点”),团队让视觉语言模型(VLM)和生成模型一起训练,让 AI 能“翻译”不规则指令,变成自己能理解的结构化信息,大幅提升了实际使用时的体验。
港产 AI 新标杆:技术突破背后的产业价值与科研意义
DreamOmni2 的横空出世,不仅是一次单一模型的技术升级,更成为香港多模态 AI 科研实力的“代表作”,为本地科技生态带来多重价值。
从产业应用来看,它打破了 AI 图像创作领域“闭源模型垄断高级功能”的格局——普通用户无需付费,在 Hugging Face 上搜索“DreamOmni2-Edit”或“DreamOmni2-Gen”,上传图片、输入指令就能体验以往只有付费闭源模型才有的功能;对于设计师、内容创作者而言,它大幅降低了复杂创意的实现门槛,比如做服装风格迁移时,无需反复调试参数,一张参考图+一句指令就能精准还原面料质感与色彩;企业也可基于 GitHub 开源代码(https://github.com/dvlab-research/DreamOmni2),定制符合自身需求的创作工具,应用于数位营销、产品设计等场景。
从科研层面来看,DreamOmni2 提供了“数据-框架-训练”三位一体的系统性解决方案,为行业树立了新标杆。其独创的三阶段数据构建范式,索引编码、VLM 联合训练等框架优化思路,也为其他多模态模型的开发提供了可复用的技术路径。目前,项目在 GitHub 的星标还在持续增加中,全球开发者围绕模型优化、功能拓展展开活跃讨论,形成了开放协作的技术生态。
更重要的是,作为贾佳亚团队深耕多模态领域的又一成果——从之前的 Mini-Gemini 视觉语言模型、ControlNeXt 生成控制工具,到如今的 DreamOmni2,团队已逐步构建起覆盖“感知-理解-生成”的全链路技术栈。这不仅证明了香港在 AI 前沿领域的研发能力,更为本地“学术研究-技术转化-产业落地”的生态闭环提供了优质样本,未来或将吸引更多人才与资源投入香港 AI 领域,推动本地科技产业实现更高质量的发展。







 查看更多
查看更多














